Pick, premier s.g.b.d. au monde!
Le 19 mars 1965 richard pick et don nelson remettent le dossier des spécifications du projet girls à la société twr pour l'armée américaine, girls, pour generalized information retrieval language and system, projet d'un langage simple d'interrogation, afin de créer un système permettant la gestion de la configuration des composants de l'hélicoptère cheyenne ce sera un modèle de données et un système multi-utilisateurs et multi-tâches, basé sur le concept d'un ordinateur virtuel, permettant notamment d'assurer le portage système sur tout type d'architecture matérielle, et la facilité d’accès aux éléments de la base de données pour des non-informaticiens .
En 1968 le système de récupération de données est nommé gim (generalized information management) et est implémenté sur un ibm 360, il a alors la plupart des fonctionnalités du langage de pick (connu aujourd'hui sous le nom d'english) et le langage d'extraction de données fut nommée girls (generalized information retrieval language system). Trw essaya de breveter toutes les fonctionnalités de gim, girls et dm-512 mais échouèrent. L'armée américaine passa dans le domaine public toutes les fonctionnalités développées par trw pour les hélicoptères cheyenne. Dick pick créa alors la compagnie syscom pour poursuivre ses recherches.
Une version mise à jour etait encore en service à la cia en 1981.
Le girls n'a jamais été utilisé à des fins commerciales. Dick pick a poursuivi ses recherches dans ce sens, et aucun veto du département américain de la défense ne s'y est opposé, car le résultat final ne mettait pas la sécurité nationale en danger.
Relativement confidentiel lors de sa conception, l'operating system pick n'a cessé de se répandre régulièrement depuis.
En 1970 la première implémentation commerciale de pick par la société microdata s'intéressa aux travaux de pick et acquit les droits des systèmes pick. En 1973 microdata livra sur sur l'uc 8 bits 1600 un système nommé « reality operating system ». Reality était distribué à travers le monde et notamment le distributeur britannique cmc qui fusionna en 1976 avec microdata.
Suite à la faillite de syscom en 1971, dick pick fonda « pick & associates » en 1972, renommée ensuite « pick systems », actuellement « raining data ».
Microdata s'adresse alors à intertechnique pour lui demander de fabriquer et de lui fournir une carte micro programmée pouvant interpréter le jeu d'instructions. Cela se passe en 1973, et c'est ainsi que naît le système réalité d'intertechnique.
En 1974, la société intertechnique obtient l'exclusivité de richard pick pour l'europe et cmc se consacre à la grande bretagne.
Le succès est assez modéré entre 1973 et 1976, avec environ un millier d'utilisateurs.
Beaucoup de choses ont changé depuis. en effet, cmc est d'abord repris par microdata qui, à son tour, est absorbé par mac donnell douglas.
A la même époque, dick pick quitte microdata qui l'a déçu, et fonde pick and associates (1972). Les systèmes evolution de pick and associates sont en fait des ordinateurs intertechnique sur lesquels le pick est installé.
Le même processus se passe avec ultimate, qui implémente pick sur les minis level 6 de honewell. Par la suite, pick est installé sur des matériels dec et tandem. En 1982, pick tourne sur les séries 43xx d’ibm, sur pertec, altos, fujitsu microsystem. le système pick est alors disponible sur presque toutes les plate formes: helwett-packard, digital equipment, motorola, att/ncr, etc... au milieu des années 80, le magazine var affirme: "le nombre d’applications développées par les revendeurs est plus important sous les environnements pick que sous unix.". Aujourd’hui, environ 4000 applications et 4.000.000 d’utilisateurs dans le monde.
La société pick system, sous sa forme définitive et actuelle, est née le 21 mars 1975.
Entre-temps, ultimate, qui a les droits sur le pick, l'a installé sur le lsi-11 de digital afin de combler une lacune dans le bas de gamme de son offre.
En 1977 microdata poursuivit pick en justice pour vol de secrets de fabrication. La justice établit que dick pick n'avait pas le droit d'utiliser les noms reality et english et microdata n'avait pas le droit d'utiliser le mot pick. Dans le même temps dick pick accorda des licences de ce qu'on appelle maintenant « pick » à de nombreux constructeurs et vendeurs qui ont produit des variantes différentes de « pick ». le véritable nom étant sgbdr mv, pick étant la marque du premier sgbdr mv.
C'est vers 1979 que les premiers systèmes de type pick font leur apparition. Le système information, conçu par devcom à l'usage des ordinateurs de la gamme 50 de prime, est un proche très puissant. Il a cependant le désavantage de travailler en deuxième couche du système d'exploitation maison: le primos. en conséquence, il est très gourmand en mémoire centrale, mais il offre en revanche d'excellentes possibilités de communications. c'est une de ses caractéristiques remarquables.
Cosmos a également implémenté revelation en combinaison avec le ms-dos sur l'op ibm.
Par la suite, vmark software commercialise universe, variante de pick sous unix. autre variante de pick sous unix, unidata, qui utilise également la conception de la base de données pick sous unix.
Pendant tout ce temps, dick pick, toujours très actif, dans sa société pick systems, s'est entouré d'une équipe commerciale extrêmement compétente. Il a ainsi décroché plusieurs contrats de licence avec plusieurs constructeurs pour une installation optionnelle de pick sur leurs machines. On murmure que le coût d'une licence semblable se négocie entre un demi et un million de dollars.
En 1984, pick systems lance une version qui fonctionne sur les personal computers qui arrivent en force sur le marché. Cette première version"pc", la r83, fonctionnait déjà sur les pc xt !!. L’utilisation optimale des ressources de la machine, caractéristique extraordinaire des versions natives, permet d’obtenir des performances honnêtes à plusieurs utilisateurs pour l’époque. Il est vrai que c’est le pc at qui a offert un environnement de travail confortable pour un nombre d’utilisateurs plus grand. Sur un pc at 286, on pouvait facilement connecter six utilisateurs sans problème.
Pick system continue en plus à contrôler très attentivement les installations sur de nouveaux systèmes. Cette politique de pick, un, unique et indivisible, à l'antipode de celle qui a toujours cours pour unix, garantit une portabilité quasi totale d'un système à l'autre des logiciels d'application. Les deux exceptions que l'on peut citer sont microdata et ultimate qui ont continué à développer leurs systèmes respectifs avec une certaine indépendance vis-à-vis de la ligne pick.
Cette politique de pick va exactement à l'inverse de celle qui a cours pour unix. en effet, ce système d'exploitation s'est diversifié de manière étonnante: unix system v, unix version berkeley, xenix, sinix, aix, unix sco, etc ...
En 1988, pick lance advanced pick, nouvelle version qui annonce le détachement de la base de données du système d’exploitation proprement dit. En effet, cette version existe en version native et en version fonctionnant sous unix. Le système de base de données unique de pick est donc devenu quasi universel, car n’oublions pas que toutes les versions sont portables ...
Les utilisateurs indéfectibles de unix peuvent donc également disposer d’un modèle de base de données multidimensionnel qui n’existe toujours pas à l’heure actuelle chez les concurrents. (oracle 7, sybase sql server 11, informix universal server, microsoft sql server, unidata dbms, universe db²ms, arbor essbase, comshare commander, iri/oracle express, red brick warehouse)
Pick est une base de données multi-niveaux qui continue à intégrer les technologies qui se développent au fil du temps. Il est remarquable de constater que tous les concepts définis par dick pick au départ (il y a quarante ans!!!) restent aujourd’hui encore en avance sur les autres.
Actuellement, le système pick est disponible sur la presque totalité des systèmes. en outre, certains constructeurs ont axé la totalité de leur gamme sur pick exclusivement.
Le milieu des années 90 voit la sortie du tout dernier système pick: D3.
D3 conserve évidemment tous les principes de la base de données multidimensionnelle en s’adaptant aux technologies actuelles: client-serveur, développement orienté objet, traitement distribué, etc...
D3 fonctionne évidemment sous linux et sous windows xp . Le fait que linux tende à remplacer windows nous permet donc d’envisager l’avenir de façon sereine, car quelle que soit l’issue du "combat", l’investissement consenti dans le logiciel d’application sera toujours préservé.
Dans le même temps, un licencié pick de la première heure, general automation, après avoir fabriqué pendant de nombreuses années des machines pick native, a lui aussi élaboré une version pick qui fonctionne sous linux et sous windows xp, respectivement mventerprise et mvbase. Il est remarquable de noter que ces versions ne sont pas des "pick-like" comme universe ou unidata. Ce sont des versions conformes aux standards pick que l’on retrouve dans toutes les "bonnes" versions. l’offre de solutions sous pick est donc vaste et performante.
Il faut mentionner également que ga conserve une version open architecture de pick dans sa gamme de produits. en effet, pick systems avait commencé le développement d’une version oa et a finalement abandonné son développement.
Cette version oa a été achevée à l’extérieur de pick par l’équipe qui y travaillait à l’époque, chez rexon, puis chez alphamicro, puis chez sequoia, puis chez general automation en fin de course par le jeu des rachats de sociétés. Cette version, en mode natif, aux performances extraordinaires, existe encore et porte le nom de sequoia pro. A titre d’exemple, nous avons encore des applications qui tournent à l’heure actuelle sur des pc 486 dx66, 64 méga de ram, avec 48 terminaux et un niveau de performance difficilement égalé par de gros systèmes sous unix... ou sous linux...
Quelle que soit la version choisie, il semble, en l’état actuel du marché, que ce soient les versions qui tournent sous linux qui sont promises à un succès important.
En effet, on a longtemps reproché à pick son aspect soi-disant "fermé". C’était en partie exact et très nettement exagéré. Nous avons toujours rangé cet argument au rang des arguties commerciales invoquées par la concurrence. cet argument est devenu fantaisiste depuis l’avènement des versions unix, et définitivement dénué de fondement avec windows et linux et le passage en domaine public des brevets pick et la sortie de versions libre de pick
L’intégration de pick et de xp ou linux est en effet remarquable car l’intégration harmonieuse des deux systèmes permet d’ajouter leurs qualités réciproques sans restrictions.
Le support des standards ouverts tels que sql, odbc, ocx, ole... dans un environnement client/serveur, ne laisse aucun doute sur l’ouverture et l’intégration de pick et de windows ou linux.
Enfin, l’intégration d’une base de données pick avec le web ne pose pas de problème. On peut donc mettre les données contenues dans les fichiers pick à la disposition de tous les utilisateurs d’un intranet ou de l’internet et il existe plusieurs implémentations en logiciel libre.
II. Description generale
Décrire pick en quelques mots n'est pas simple.
En effet, pick nous offre à la fois:
| un système d'exploitation multi-tâches et multi-utilisateurs (versions natives) | |
| une base de données évolutive | |
| une série de langages de programmation | |
| un langage de quatrième génération, la langue maternelle de l'utilisateur | |
| un traitement de texte | |
| un langage procédural | |
| un langage de gestion des ressources | |
| des limites définies par l'architecture matériel |
Toutes ces caractéristiques sont indissociables et incomparables à celles des systèmes traditionnels.
En effet, pick est bien plus qu'un sgbd. il assure bien sûr toutes les fonctions d'un sgbd traditionnel mais assure aussi la gestion de la mémoire, gestion du disque, entrées et sorties des terminaux, etc..., mais en plus, il comporte comme nous venons de le voir, toute une série de fonctions qui constituent des 'applications' pour les autres.
Il offre ainsi un véritable "environnement d'exploitation" idéal pour toute situation où la mémorisation, la recherche, et la présentation de données revêtent une importance primordiale.
On constate donc que cet environnement de travail est en fait un environnement idéal pour tout ce qui concerne la gestion des affaires.
On peut même dire que c'est le seul qui réponde aussi parfaitement à chaque aspect pratique de tous les domaines de la gestion.
Hardware freedom forever est une expression qui traduit la philosophie pick.
Vous pouvez la traduire par "portable".
Vous pouvez appeler cela "indépendant de la machine".
Mais la signification principale de cette expression est que vous pouvez choisir votre logiciel sans vous préoccuper du choix hardware.
Le système pick a été conçu à l'origine pour des machines 16 bits équipées d'un disque dur dont la capacité était au minimum de 10 méga bytes .
Le fait que pick soit multi-tâches et multi-utilisateurs lui conférait un avantage indéniable sur ses concurrents.
La configuration at permettait ( et permet encore) à huit utilisateurs de travailler simultanément. Ce nombre pouvait monter jusqu'à seize pour un 80386. (nous parlons ici de configuration réelle et pas de configuration "marketing")
Pick n'est limité que par la capacité hardware. Il exploite le matériel sur lequel il est implanté, il n'y a aucune limite dans le système lui-même quant aux nombres de terminaux, de fichiers, etc...
Par exemple, une installation qui tire 48 terminaux avec un 486 dx66, 64 méga de ram et un disque scsi de 250 méga.
Nous pouvons donc dire sans risque que, dans les versions actuelles, sous linux ou xp, on peut brancher plusieurs milliers de terminaux, pour exploiter une base de données de n'importe quelle taille.
Le système pick est basé sur un principe courant sur de gros système informatique, la mémoire virtuelle.
En d'autres termes, la mémoire de masse constituée par le disque dur peut être considérée par l'utilisateur comme faisant partie de la mémoire centrale. En effet, le système d'exploitation se charge, de façon transparente, d'échanger les données entre le disque dur et la mémoire centrale réelle.
Pour donner une image frappante de ce type de gestion d'exploitation, il est théoriquement possible, sur un système équipé d'un disque dur de vingt méga-octets, d'exécuter un programme ayant une taille de vingt méga-octets, puisque le système va charger en mémoire centrale les pages de mémoire dont il a besoin pour travailler au fur et à mesure du déroulement du programme.
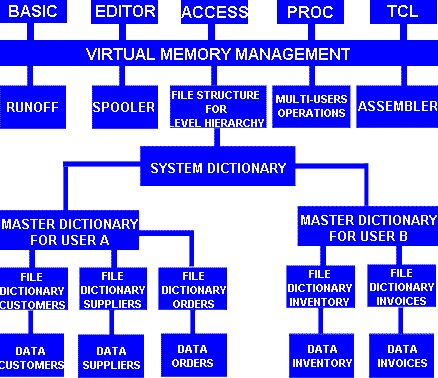
Au premier niveau, un fichier maître, appelé fichier système, contient les différents noms de comptes utilisateurs. Un nom de compte est en fait un pointeur qui permet au système de trouver le maître dictionnaire du compte utilisateur.
(voir le schéma au départ du system dictionary)
A chaque nom de compte est associé un fichier, situé au second niveau, appelé maître dictionnaire du compte (md). le md contient l'ensemble du vocabulaire mis à la disposition de l'utilisateur: les verbes, les noms, les liens, les interdictions, ainsi que les pointeurs vers tous les dictionnaires de fichiers de données accessibles au compte considéré.
Pour plus de clarté, on peut comparer un md à un directory enrichi de telle façon qu'il contient même les noms des ordres primitifs du système.
Les dictionnaires de fichiers constituent le troisième niveau de la pyramide hiérarchique. Ils décrivent la structure des données et les liens ou relations qui unissent les données contenues dans les différents fichiers.
Le quatrième niveau est constitué par les données proprement dites (fichiers clients, stocks, etc ...).
Le rôle des dictionnaires est également de donner un sens logique aux attributs des articles stockés dans les fichiers du niveau inférieur. cette description est effectuée par les articles de définition d'attributs. en résumé, un dictionnaire contient:
| des articles de définition de fichier | |
| des synonymes de définition de fichier | |
| des articles de définition d'attribut |
Les trois types d'articles des dictionnaires sont identifiés par un premier attribut qui contient un code qui les différencie (type de pointeur).
La grande particularité de pick est de proposer une structure de fichier unique qui sera adaptée à toutes les situations. pas de séquentiel, ni de direct, ni d'indexé séquentiel.
Tous les fichiers, qu'ils soient système, md, dictionnaire ou de données, sont de même type.
Les fichiers peuvent contenir un nombre illimité d'enregistrements, ou articles, qui peuvent contenir un nombre illimité de zones, ou attributs, qui contiendront des sous-zones, ou valeurs, qui, elles-mêmes, contiendront un nombre quelconque de sous-valeurs.
Pick gère automatiquement les fichiers, enregistrements, attributs, valeurs et sous-valeurs en longueur variable. ceci permet d'éviter un gaspillage de l'espace disque. (statistiquement 30 % d'économie)
Pick met à la disposition de l'utilisateur cinq outils de travail particulièrement performants.
(voir le schéma général d'un système pick, les modules touchant à la mémoire virtuelle)
Le pick basic ou basic gestion de sont vrai nom databasic est un langage simple et puissant qui, par sa conception et ses instructions spécifiques à la base de données, permet le développement rapide de programmes.
Il n'a de commun avec les basic courants que le nom et la souplesse de syntaxe. C'est un basic équivalent à pascal, par exemple, avec des instructions qui fonctionnent de la même manière, et qui permettent, pour ceux que cela intéresse, de programmer en structuré très facilement. bien que compilé, il est assisté d'un moniteur de mise au point de programmes: debugger.
Il contient également les instructions spécifiques à la gestion des fichiers pick. Ces instructions permettent de gérer les valeurs et les sous-valeurs dans les attributs des articles de fichier. Ces instructions, que nous verrons plus loin, permettent de localiser, extraire, remplacer, effacer, les attributs, les valeurs et sous-valeurs dans les articles de fichier.
Access est le langage de quatrième génération par excellence. Il sera l'english pour l'anglais, le nederlands pour le néérlandophone, le français pour le francophone,...
C'est le langage d'interrogation de la base de données. il permet à l'utilisateur:
| d'extraire des données d'un ou de plusieurs fichiers de la base de données en fonction de critères de sélection | |
| de classer ces données dans un ordre souhaité | |
| de visualiser ou imprimer ces données sous une présentation personnalisée |
Une interrogation de la base de données consiste en une phrase simple de format assez libre, qui commence par un verbe, suivi de l'objet sur lequel s'effectue l'opération, suivi de compléments constituants les critères de choix ou de sélection, puis des rubriques sur lesquelles portent ces critères.
On peut également imposer des niveaux de rupture afin de faire des sous-totaux et un total général.
Viennent ensuite les spécifications de sorties qui indiquent les rubriques que l'on désire éditer à l'écran ou à l'imprimante, citées dans l'ordre où on veut les voir apparaître.
Proc est un langage interprété d'enchaînements de plusieurs commandes (access, basic, ...). une proc est une procédure cataloguée sous un nom qui s'ajoute au vocabulaire de l'utilisateur.
Toute opération de gestion est un enchaînement d'opérations élémentaires. Cet enchaînement est appelé 'procédure' et proc est le langage de déclaration de ces procédures cataloguées.
On peut le comparer au langage de contrôle des travaux en usage sur de grands systèmes informatiques (job control langage). Pick rappelle d'ailleurs ici ses origines, puisqu'il a été développé au départ sur de grosses unités centrales.
On peut, par exemple, exécuter une instruction de access via une instruction mono-mot, orienter le résultat d'une sélection access dans un programme basic, appeler d'autres procs ou des fonctions pick normées comme des fonctions d'archivage.
On peut ainsi déclencher des procédures complexes qui durent plusieurs heures.Il est à noter que certaine implantation récente de pick ne possédent plus cet outil qui fut juger obsoléte au vue des performances des autre outils
Tcl (terminal control langage) est l'organe de dialogue entre l'utilisateur et l'ordinateur. Il comprend plus de 300 commandes qui constituent le vocabulaire de base mis à la disposition de l'utilisateur. Chacune de ces commandes peut être traduite dans la langue de son choix.
Ces commandes permettent de gérer les ressources du système, de modifier ses caractéristiques, de créer des comptes et des fichiers, etc... par exemple, les verbes tcl permettent d'attacher la bande magnétique, de commander une sauvegarde, de lire une bande magnétique, de restaurer un compte précédemment sauvé, de gérer le spooler, de compiler un programme basic, de mettre un processus en sommeil ...
Editor permet la création, la modification et la suppression de n'importe quel élément, ou article, de la base de données.
Il permet notamment d'encoder et de modifier les sources des programmes basic. Dans des implantations modernes de pick bien souvent un éditeur pleine page remplace avantageusement cet outil à l'ergonomie déficiente et/ou des éditeurs externes tel ultra-edit peuvent étre utilisé.
Le système pick comporte :
| un nombre quelconque de fichiers qui peuvent contenir | ||||||||||||||
| un nombre quelconque d'articles qui peuvent contenir | ||||||||||||||
|
||||||||||||||
Tous les fichiers, articles, attributs, valeurs et sous-valeurs sont de longueur variable.
La taille des fichiers n'est limitée que par l'espace disque disponible.
La longueur des articles était limitée à environ 32000 caractères (cela dépend du nombre de séparateurs). Cette restriction n’est plus de mise à l’heure actuelle.
Les fichiers sont organisés dans une structure hiérarchisée, où un fichier du niveau supérieur définit entièrement les fichiers associés du niveau immédiatement inférieur. ainsi, un fichier définissant un ou plusieurs fichiers du niveau inférieur est appelé dictionnaire pour ces fichiers. Les données dans un fichier sont retrouvées par l'intermédiaire du dictionnaire.
Un article est identifié par son "nom" unique dans le fichier, appelé "identificateur d'article" ou id-art.
Cet identificateur est utilisé par le système pour le calcul de l'adresse à laquelle cet article est écrit dans la mémoire virtuelle, et donc l'endroit où il va être relu chaque fois que ce sera nécessaire.
Le calcul de l'adresse se fait selon une technique de hashing value. tous les accès fichiers se font pratiquement en accès direct. en réalité, le fichier comporte des groupes d'articles, et le système calcule l'adresse de la première page de chaque groupe. il pointe alors sur cette page et poursuit une recherche séquentielle à l'intérieur de ce groupe jusqu'à ce qu'il rencontre l'article recherché.
(voir le mode de calcul de l'emplacement d'un article dans un fichier)
Les données sont rangées dans un article sous forme d'attributs, de valeurs et de sous-valeurs. le contenu physique d'un article se présente comme une suite de ces éléments séparés par des caractères spéciaux appelés respectivement séparateurs d'attributs (sa, am), de valeurs (sv, vm) et de sous-valeurs (ssv, svm).
(voir le schéma de la structure d'un fichier)
La structure de base d'un fichier comporte les éléments suivants:
Le fichier étant un ensemble d'articles, le groupe est un ensemble de partitions chaînées dans lequel les articles sont rangés en séquence. le nombre de groupes dans un fichier est défini par le modulo, et la taille de chaque groupe par la séparation, c'est à dire le nombre de pages qu'il comporte.
| la base est l'adresse de la page mémoire à laquelle commence le premier groupe | |
| le modulo est le nombre de groupes dans le fichier | |
| la séparation est la taille initiale des groupes du fichier, en nombre de pages |
Lors de la création du fichier, le système réserve un espace primaire égal en nombre de pages, au modulo multiplié par la séparation. Cet espace primaire est toutefois extensible, puisque le système choisi des pages de débordement dans l'espace libre de la mémoire dès qu'il atteint la limite du groupe dans lequel il veut écrire. il n'y a donc pas de limite théorique à la taille d'un fichier.
(voir le schéma structure de base d'un fichier)
Il est toutefois judicieux de choisir convenablement ces paramètres afin d'optimaliser les performances du système. Il existe des règles qui permettent de ne pas attribuer ces critères au hasard.
Bien qu'il soit important de comprendre le format physique d'un article, l'utilisateur accède aux articles des fichiers par l'entremise du système qui lui présente les articles d'une façon plus évidente et plus facile à traiter.
Pour le système, le contenu de chaque attribut n'est qu'une chaîne de caractères quelconques; il ne comprend pas le sens logique des données stockées.
Le processeur access ajoute une dimension supplémentaire à la structure des données, par l'utilisation des dictionnaires. le mot "dictionnaire" n'est pas choisi au hasard : le dictionnaire donne un sens logique aux données stockées dans les articles, "explique" leur signification. Cette signification est évidemment choisie par l'utilisateur
Nous avons vu que pick gérait quatre niveaux de fichiers.
Le dictionnaire système, ou fichier système, contient des articles de fichier qui sont en fait des pointeurs qui permettent de trouver le maître dictionnaire du compte d'un utilisateur.
Le maître dictionnaire du compte d'un utilisateur contient le vocabulaire à la disposition de cet utilisateur, et pointe sur les dictionnaires des fichiers de données associés à ce compte.
Les dictionnaires de fichiers de données décrivent à leur tour les données stockées dans les fichiers du dernier niveau, les fichiers de données elles-mêmes.
Un dictionnaire peut donc contenir:
| des articles de définition de fichier | |
| des synonymes de définition de fichier | |
| des articles de définition d'attribut |
Les trois types d'articles de dictionnaire sont identifiés par un code contenu dans le premier attribut.
Nous nous bornerons ici à donner un exemple d'article de dictionnaire définissant un attribut de fichier de données
| id-art: nom | id-art: adr | |
| 01 a 02 1 03 nom du client 04 05 06 07 08 09 l 10 25 |
01 a 02 2 03 adresse client 04 05 06 07 08 09 l 10 30 |
01 pointeur de
type a décrivant un attribut 02 le nombre indique le rang de l'attribut dans l'article 03 indique le titre qui sortira dans toutes les éditions 04 05 06 07 reçoit les codes de conversion 08 reçoit les codes de corrélations 09 indique le cadrage de la donnée à l'édition 10 indique la longueur prise en compte pour l'édition de l'attribut. nota: les zones 4, 5 et 6 sont parfois utilisées pour des descriptions de fichiers particulières: attributs associés, structure arborescente de fichier, etc. |
(voir un schéma général de la mémoire virtuelle et de son fonctionnement)
Le pick basic, de sont vrai nom databasic, a été spécialement conçu pour être utilisé dans le contexte de base de données pick.
Il n'a que le nom en commun avec le basic traditionnel que vous connaissez.
C'est un compilateur particulièrement perfectionné: programmation structurée, modularité assurée par des fonctions de sous-routines externes, connaissance de la base de données, support de structures variables reflétant exactement celle de la base de données elle-même
Il se caractérise essentiellement par :
| un jeu puissant d'instructions d'accès et de mises à jour des fichiers (c’est la moindre des choses...) | |
| de nombreuses fonctions de traitement de chaînes de caractères et d'articles de fichiers. | |
En effet, le pick basic comporte les instructions qui permettent de localiser, d'extraire, de remplacer, d'insérer, d'effacer, des attributs, des valeurs, des sous-valeurs, d'un article de fichier pick.
| une syntaxe permettant une programmation structurée | |
| un processeur de mise au point et de trace | |
| des instructions d'entrées/sorties terminal extrêmement souples | |
| une mise en format simple pour l'édition sur un terminal ou sur l'imprimante |
(dans le style "mode-école" programmation structurée, on peut évidemment ajouter de nos jours la programmation orientée objet)
Exemple:
loop
instructions
until expression do
instructions
repeat
L'editeur est un processeur qui permet la modification interactive de tout article résidant dans la base de données. Il utilise le concept de ligne courante, autrement dit, à tout instant, une ligne en cours d'édition peut être listée, modifiée, supprimée, etc.
L'editeur est un outil de développement de programmes et non un outil d'exploitation. Les conflits d'accès en contexte multi-utilisateurs ne sont pas gérés par ce processeur.
L'editeur comporte les caractéristiques suivantes :
| deux tampons temporaires de longueur variable | |
| positionnement absolu et relatif de la ligne courante | |
| sollicitation du numéro de ligne en entrée | |
| fusion des lignes issues d'autres articles | |
| localisation et remplacement d'une chaîne de caractères | |
| suppression conditionnelle et inconditionnelle de lignes | |
| mise en forme en entrée/sortie | |
| préstockage de commandes |
Fonctionnement de l'editeur
L'editeur utilise deux tampons pour l'édition d'un article. L'article est copié dans un tampon et les mises à jour sont assemblées dans l'autre. Une commande f fusionne les mises à jour avec l'article puis fait basculer le fonctionnement des tampons
Le terminal control language ou lgr (langage de gestion des ressources) est l'interface principal entre l'utilisateur d'un terminal et les différents processeurs du système.
La plupart des processeurs sont appelés directement à partir de tcl, au moyen d'une seule instruction, et rendent le contrôle à tcl après avoir achevé leur traitement. Certains, cependant, conservent le contrôle du terminal jusqu'à une intervention explicite leur faisant rendre le contrôle à tcl (l'editeur par exemple).
Tcl s'attend à ce que le premier mot d'une phrase soit un "verbe". dans le système, il y a trois types de verbes :
| les verbes access | |
| les verbes tcl-1 | |
| les verbes tcl-2 |
L'un des avantages de pick est la possibilité d'adapter le vocabulaire aux besoins de chaque utilisateur. Puisque les verbes sont dans le maître dictionnaire (m/dict) propre à chaque utilisateur, il est possible d'y ajouter du vocabulaire sans affecter les autres. De plus, il est possible de créer pour chaque verbe, un nombre illimité de synonymes.
Les verbes access feront l'objet d'un chapitre particulier.
Les verbes tcl-1 sont ceux qui exécutent des fonctions qui n'impliquent pas d'accès à un fichier. par exemple, create-file, who, sp-assign ...
Les verbes tcl-2 au contraire, impliquent l'accès à un fichier. Par exemple, compile, catalog, copy, edit, run ...
Tous les verbes tcl acceptent une liste d'options. Certaines de ces options ont leur équivalent en access.
Exemples
f saut de page entre l'édition de deux articles successifs
o autorisation d'écriture sur les articles existants
s suppression des messages d'erreur
p sortie vers le spooler
Dans un système informatique, il est assez facile d'emmagasiner des données. On peut facilement garnir n'importe quel fichier avec n'importe quelles informations.
L'information, dans la plupart des cas, est là, dans votre système.
Le problème se pose alors de savoir comment l'exploiter.
Comment y accéder ? Comment la consulter ?
Pick répond naturellement à cette question par sa conception même.
En effet, la base de données est assortie d'un langage de la quatrième génération proche du langage naturel, qui permet d'extraire les renseignements dont vous avez besoin, au moment où vous en avez besoin.
Access est un langage utilisateur d'accès direct aux données mémorisées dans le système.
Une phrase access consiste en une phrase de format relativement libre. Elle doit contenir dans l'ordre : un verbe à l'infinitif, suivi de l'objet sur lequel s'effectue l'opération, éventuellement suivi de compléments constitués par des critères ( de choix ou de sélection) ainsi que des rubriques que l'utilisateur désire examiner.
Le résultat peut être soit dirigé sur l'écran utilisateur, page par page, soit mémorisé, soit dirigé sur imprimante selon une mise en page personnalisée pour obtenir une liste plus facile à consulter.
Les rubriques mentionnées en complément dans la phrase doivent faire partie d'un vocabulaire déclaré et renseigné concernant l'objet. Ce vocabulaire doit être défini dans ce que nous appelons la partie "dictionnaire" spécifique au fichier consulté.
Une interrogation répétitive peut être mémorisée sous une commande procédurale (proc) cataloguée.
Syntaxe
| sujet | vous |
| verbe | action (list, sort, select, sselect, ...) |
| complément d'objet direct | fichier |
| préposition | sélection
hiérarchisée (by, by-exp,
...) sélection conditionnelle (with, without,...) |
| complément d'objet indirects | critères de sélection |
| quelques
verbes access list count select qselect save-list edit-list ...... |
quelques
prépositions by with without .... |
|||
| quelques
modificateurs de sortie d'état impr heading sup-det footing .... |
quelques
modificateurs d'édition total break by-exp .... |
|||
Aspect pratique
Le verbe doit être le premier mot.
La désignation du fichier autorise l'accès soit aux données soit au dictionnaire du fichier.
La liste des attributs peut être donnée explicitement en utilisant les attributs définis dans le dictionnaire des fichiers. Si aucun attribut n'est spécifié, les éventuels attributs implicites définis dans la liste du dictionnaire des fichiers seront utilisés pour définir la visualisation des enregistrements.
Les critères de sélection déterminent l'article du fichier sur lequel s'effectuera l'opération. Si aucun critère n'est spécifié tous les articles seront traités. Il est possible de faire plusieurs références directes à des articles par un seul ordre et d'effectuer des traitements conditionnels en utilisant la préposition "with"; dans ce cas, tous les articles sont passés en revue mais ceux qui répondent aux critères sont les seuls traités. L'opérateur with peut être une combinaison simple ou complexe de noms d'attributs, d'opérateurs arithmétiques, d'opérateurs logiques et de valeurs.
Les liens divers sont utilisés pour modifier l'action du verbe ou agir sur la présentation des résultats.
Quelques exemples
list clients
Cette phrase va déclencher le listage de tous les articles du fichier clients. La liste contiendra le numéro des articles (clé de l'enregistrement) si aucun attribut implicite n'est défini. sinon la liste contiendra tous les renseignements découlant des attributs implicites contenus dans le dictionnaire du fichier clients. (les attributs implicites ont comme clef un numéro; access les prend dans l’ordre ascendant jusqu’à la première interruption de séquence)
On peut également nommer explicitement les attributs qui doivent être visualisés à partir du fichier clients.
lister clients adresse telephone fax
L'instruction trier utilise un critère de sélection conditionnel. Tous les articles sont passés en revue et ceux qui répondent au critère de sélection sont les seuls visualisés dans l'ordre du tri.
trier clients avec localite = "marseille"
Toute opération de gestion est un enchaînement d'opérations élémentaires. Cet enchaînement constitue une procédure et proc permet de déclarer ces procédures et de les cataloguer.
Proc est un langage interprété qui permet d'enchaîner des phrases access, des programmes basic, et des affectations de ressources par des fonctions tcl.
Proc permet:
| un dialogue conversationnel | |
| la transmission d'arguments et de paramètres | |
| des tests sur des valeurs ou des structures | |
| des modules et utilitaires systèmes | |
| des branchements conditionnels et inconditionnels | |
| le contrôle du système et des périphériques par la surveillance des codes d'état générés par le système. |
Proc est l'équivalent du jcl (job control langage) en vigueur sur les grands système.
Chez pick, il est plus puissant car il dispose de possibilités conditionnelles et permet un dialogue interactif entre la procédure et le terminal.
Une procédure est généralement créée au moyen de l'éditeur et est rangée sous forme d'un article dans le maître dictionnaire de l'utilisateur.
Elle est exécutée en frappant son nom, suivi éventuellement des paramètres requis.
Proc est un interpréteur qui travaille sur des tampons d'entrées et de sortie: un tampon d'entrée primaire, un tampon d'entrée secondaire, un tampon de sortie primaire, un tampon de sortie secondaire. Les commandes de proc permettent de gérer ces tampons et de transférer des paramètres de l'un à l'autre quand c'est nécessaire.
Exemple.
select clients avec debit '2000'
ston
trier clients nom adresse cp localite debit (p)